Enterprise Data Science, Machine Learning, and AI
Jan 26, 2023
Top 10 AI Platform Use Cases For the Enterprise


Martin Durant is a Senior Software Engineer at Anaconda. In this blog post, he details fastparquet’s background, improvement plan, dependencies, and upgrades. Read on to learn how Martin has worked to better the fastparquet user experience and read-side performance.
Over the last six months, I have put considerable effort into modernizing and improving fastparquet, the Python parquet read/writing package that has been serving the PyData community for five years. With these additions, there are several features that are now possible, many things are faster, and, most importantly, nothing is slower (at least on the read side!).
A little background on myself: I started my career as an Astrophysicist and worked in multiple academic positions, including medical imaging research. After this I became a data scientist, and have been a member of the open-source Dask, Intake, Streamz, fsspec, and Zarr maintenance teams, with specializations in data access, remote file systems, and data formats. I have worked at Anaconda for six years, where I’ve primarily worked as a Software Engineer on our open-source team.
fastparquet was the first reader and writer for parquet-format big data which worked in Python without needing Spark or other non-Python tools. It offers performant conversion to/from pandas DataFrames and is well integrated with Dask. Until the arrival of pyarrow’s parquet integration, it was the only vectorized parquet engine (see also the earlier parquet-python, with which it shares some code).
As of the start of 2021, fastparquet remained one of the major packages for pandas-parquet, with ~1M downloads per month according to pypistats. However, it had not seen any substantial development in some time.
In April 2021, I created an issue detailing important desired improvements to implement. This list has been augmented in the months since, but most of the items were in the initial form. As you can see, almost all of them have been fulfilled (also see The Future section below).
The implementation of the various tasks resulted in a slew of releases, and here we will compare the read performance of versions 0.7.1 and 0.5.0.
The cramjam package appeared in 2020, linking Rust implementations of the compression codecs needed by parquet (except LZO, which no one uses!). This simplified fastparquet’s dependencies and users no longer have to seek extra packages for snappy, brotli, or zstd. In addition, cramjam can be faster in some cases.
Fastparquet was originally built with acceleration provided by Numba. This worked very well for en/decoding the various byte representations possible in the parquet spec. Unfortunately, Numba does not handle (Python) strings, so there was also some Cython code present.
We rewrote all the Numba code to Cython. This did not result in better performance, but reduced the size of the environment needed (no LLVM!) and eliminated some runtime compilation.
Finally, in PR, we are close to eliminating the need for thrift, using our own implementation.
Conda environment size

We’ve made quite a few changes to improve fastparquet, so I outlined some of the highlights that make the experience better for the user.
Loading of directories without a “_metadata” file: this was always possible but required the user to explicitly get a list of files first.
Read and write of “data page header 2”: added to the parquet spec a long time ago. Only a few frameworks are starting to produce V2 files, but we need to be able to read them. It also happens that there are genuine performance benefits to using V2.
Encoding types RLE_DICT and DELTA, for compatibility.
Nullable types and ns-resolution times, for better matching of pandas and parquet type systems. Nullable types are on by default, so optional int columns become pandas nullable Int columns on read, but the old behavior of converting to float and using NaN to mark nulls is still available.
Row-filtering: to only produce the DataFrame for the data you actually want. This is a two-step process, one to load the columns you filter on and one to apply the filter. The aim is not speed, but lower memory footprint (since parquet is a block-wise format, you do end up reading the same number of bytes).
Most of the effort went here, specifically the read-side performance. Here are some selected benchmarks. Keep in mind that benchmarks are biased and that the same measuring techniques were used to guide the optimization process. Numbers are as given by my machine.
Open dataset “split”

Some improvements were made in fsspec around listing and getting information about local files. Similarly, remote files will be fetched concurrently, when no global metadata is available, thus mitigating latency effects.
Time to first read

The difference is mostly due to no runtime compilation in 0.7.1. The import time is about the same and dominated by pandas.
Column read time
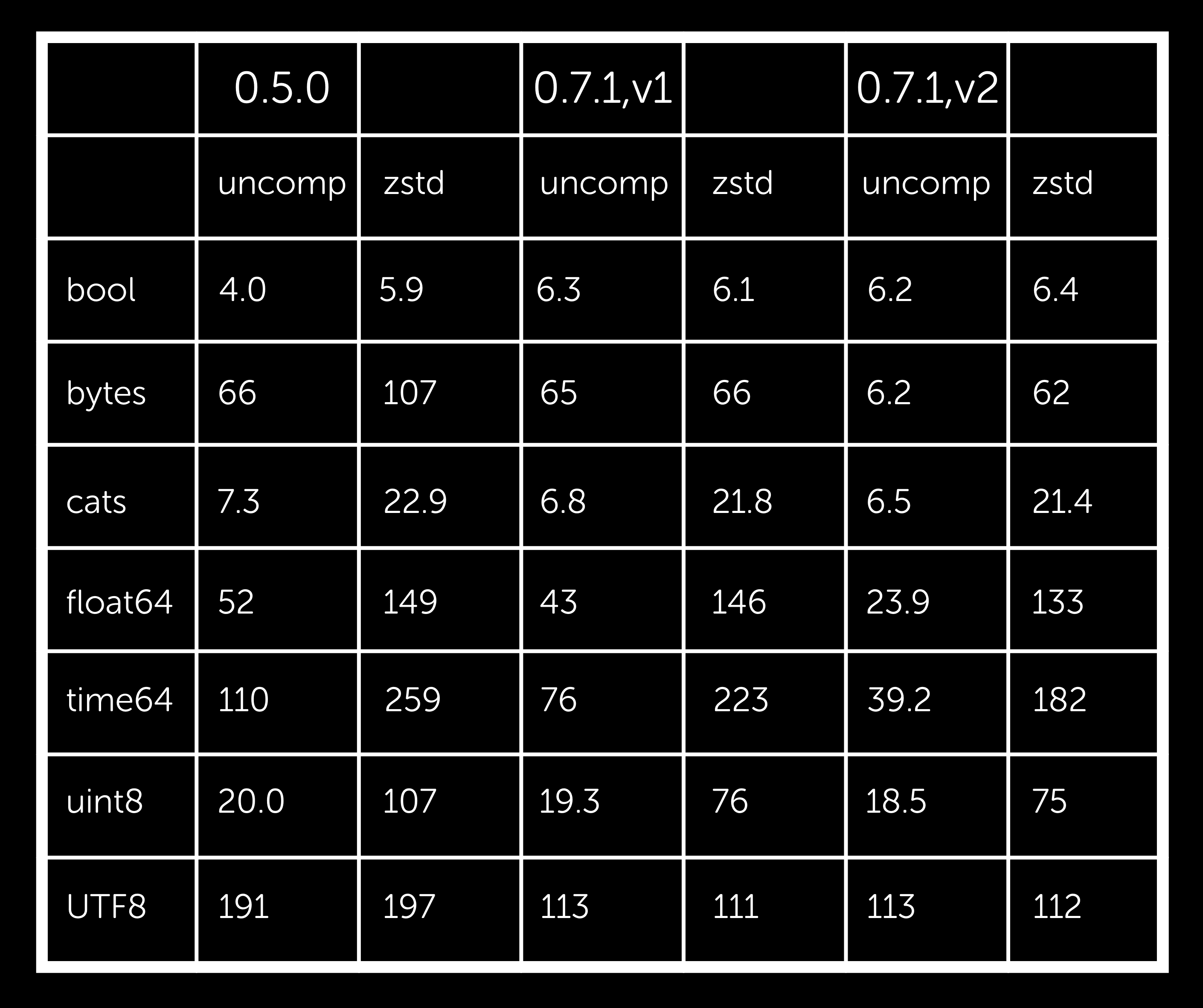
We can see that 0.7.1 is generally faster or the same (except marginally for bool) and that using V2 pages can make a big difference for float and time (and int32/64, not included). We also see that the zstd compression is the same or better and, again, V2 can make a positive impact. This difference was less apparent for gzip (always slow) and snappy (always fast, but no effective compression for random data).
The Future
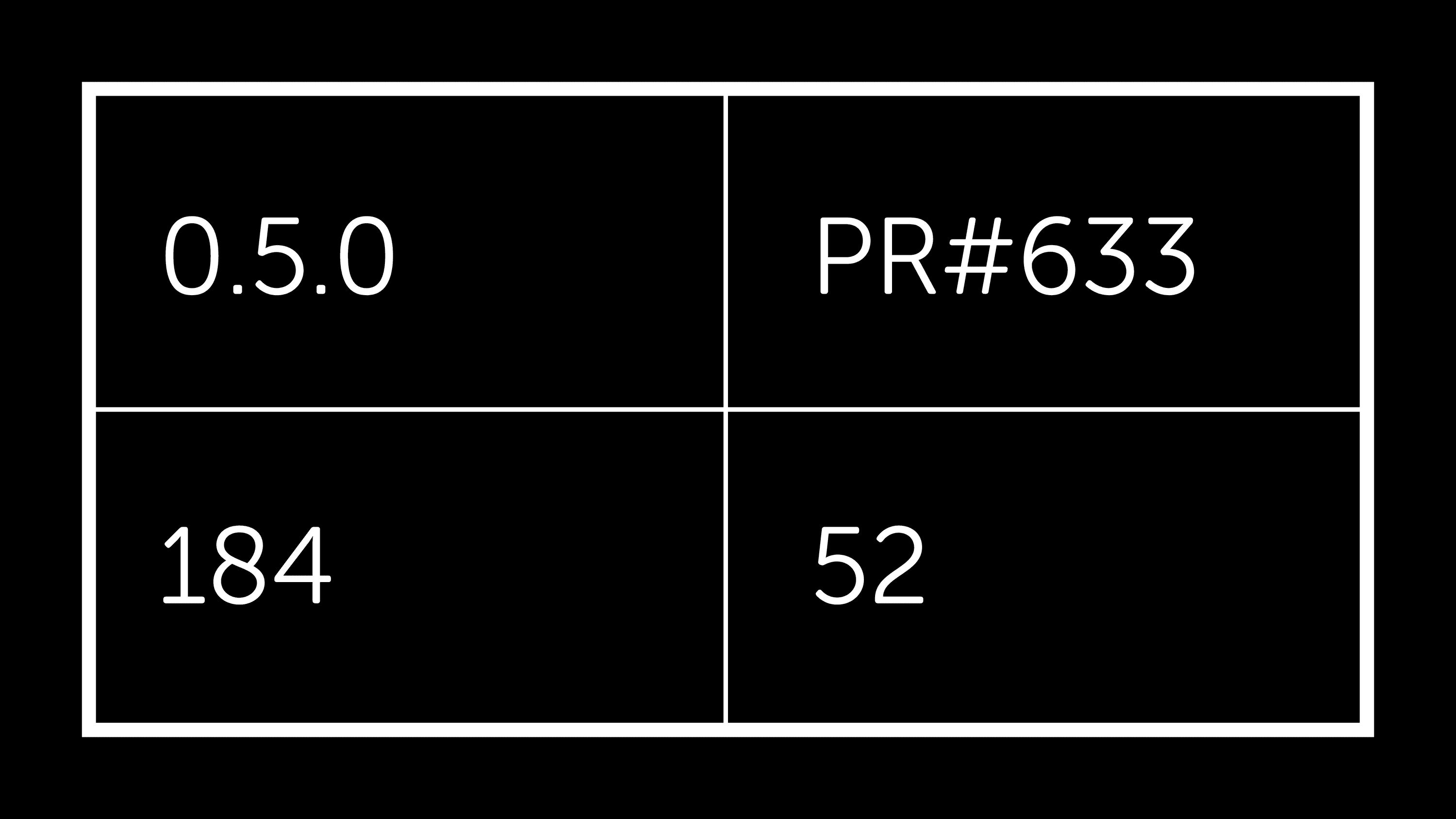
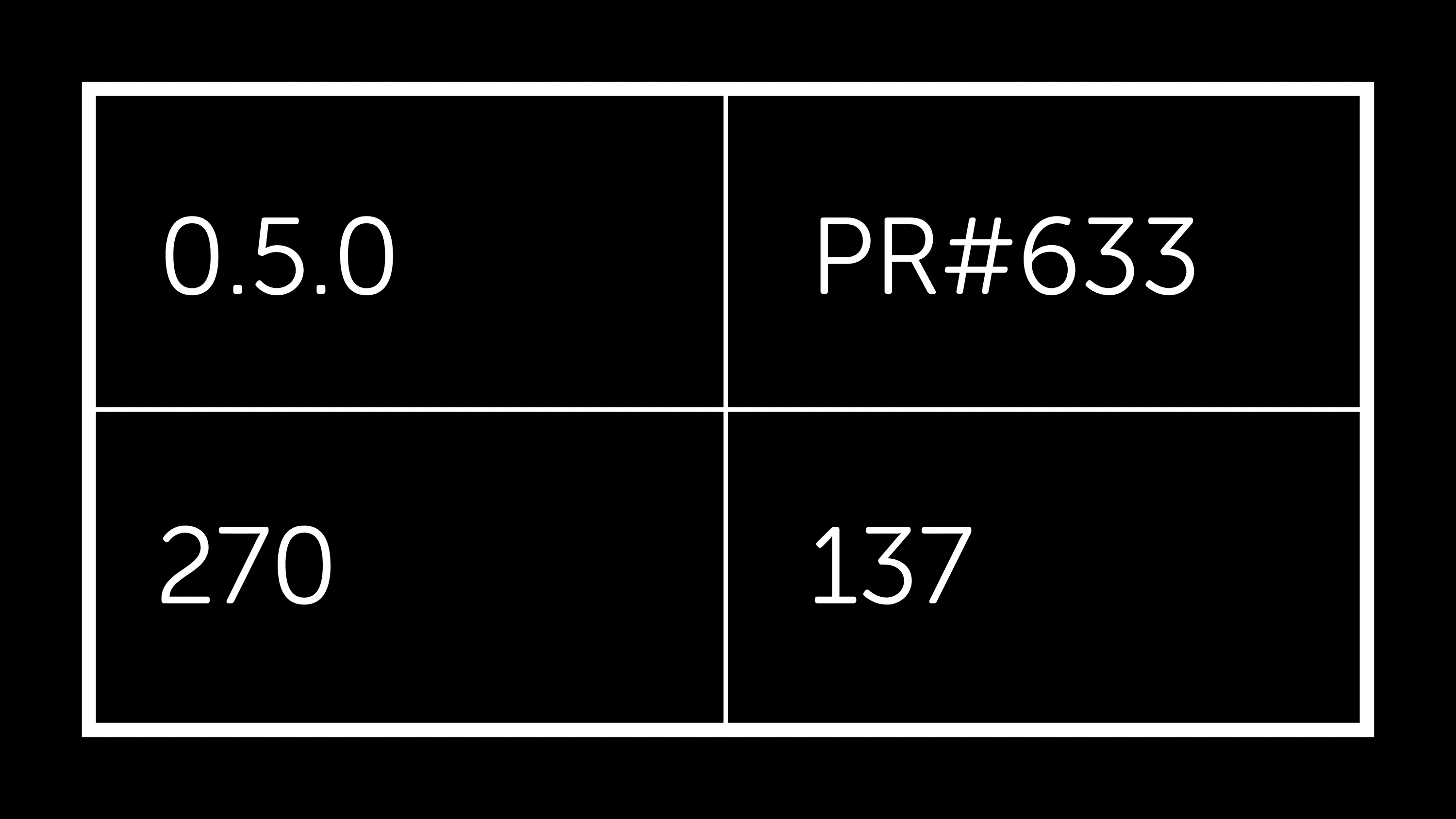
The only major effort remaining from the April plan is an implementation of thrift reading/writing that is independent of the thrift package. PR#663 does this work, and although rough edges remain, raw performance is very encouraging:
In addition to what is detailed above, other external changes were happening in the background. While some required fixes, others offered opportunities to continue improving the performance and features of fastparquet. I’m excited about the advancements we’ve made today and look forward to sharing a future update about the continued progress with this project.
Talk to one of our experts to find solutions for your AI journey.

