Open data fuels innovation. It enables people to focus more on research than on data collection, which is both time-consuming and expensive.
In this series of articles, Getting Datasets for Data Analysis tasks, we are looking at ways to access datasets from the internet. In the first part, we learned to streamline Google search to find only specific files on the web. In this part, let’s look at some of the sites, which host free and openly available datasets that can be used for data analysis tasks. Some of the sources are pretty well known in the data science community like the UCI Machine Learning Repository, Kaggle datasets, and Data.gov, so I won’t touch upon them in this article. Instead, let’s focus on some lesser-known dataset aggregator sites.
Is the Data FAIR?
Making data publicly available is vital for the benefit of the research community and society as a whole. However, the shared data should follow some essential guidelines so that it can be put to maximum use. In “The FAIR Guiding Principles for Scientific Data Management and Stewardship,” Wilkinson et al., lay down the principles for data management and data sharing. FAIR is an acronym that stands for data that is
- Findable
- Accessible
- Interoperable
- Reusable

FAIR Data principles as laid down by Wilkinson et al
Let’s now look at some of the useful sites for finding open and publicly available datasets, quickly and without much hassle.
1. Google Dataset Search

Screenshot of the Google Dataset Search page (Image by Author)
Google Dataset Search is a search engine dedicated to finding datasets. It is a search engine over metadata from data providers. This implies that it indexes over the descriptions of a dataset instead of its content. So if a dataset is available publicly, there is a good chance that it will pop up in the Google dataset search. At the time of the launch, Dataset Search had almost 25 million different datasets from across the globe. Google dataset search relies on keyword search and, like regular Google search, offers a neat autocomplete option when looking for datasets on this site.
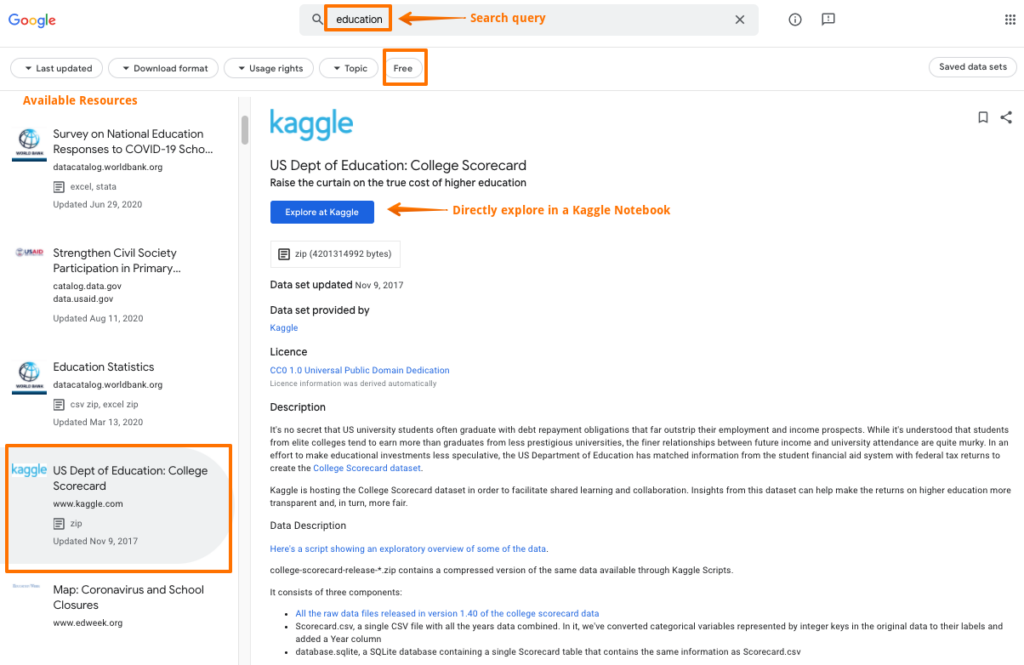
Some of the search results for the query “Education.” (Image by Author)
View a Google Dataset Search demo.
If you wish to make your own datasets discoverable in Google Dataset search, make sure you use an open standard (schema.org) to describe the properties of your dataset on your own web page.
An example of the schema for making datasets discoverable in Google Dataset Search
So, if you have a dataset on your site and you describe it using schema.org, an open standard, others can find it in Dataset Search.
🔗 Link to the site: https://datasetsearch.research.google.com/
2. OpenML

OpenML is an open data science platform meant to democratize machine learning research. It provides a large amount of data from a variety of domains, ranging from healthcare to education to climate change. Every dataset on this site has a dedicated webpage, and the data can be downloaded in multiple formats like CSV, JSON, XML, etc. OpenML can also be used to build machine learning models, and those models can then be uploaded online so that others can use them.
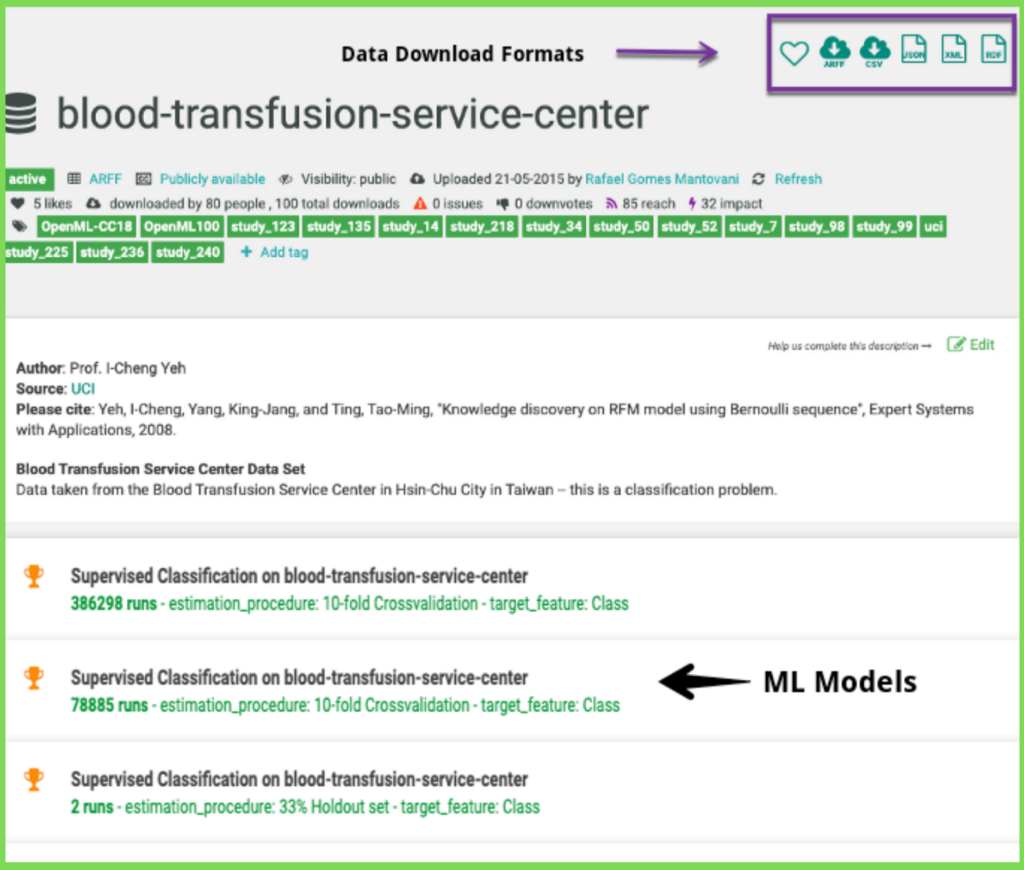
Blood Transfusion Service Center Data Set at openml.org (Image by Author)
View an OpenML datasets search demo.
OpenML is essentially designed for collaborative data science where people can share their code and results.
🔗 Link to the datasets: https://www.openml.org/search?type=data
3. FiveThirtyEight
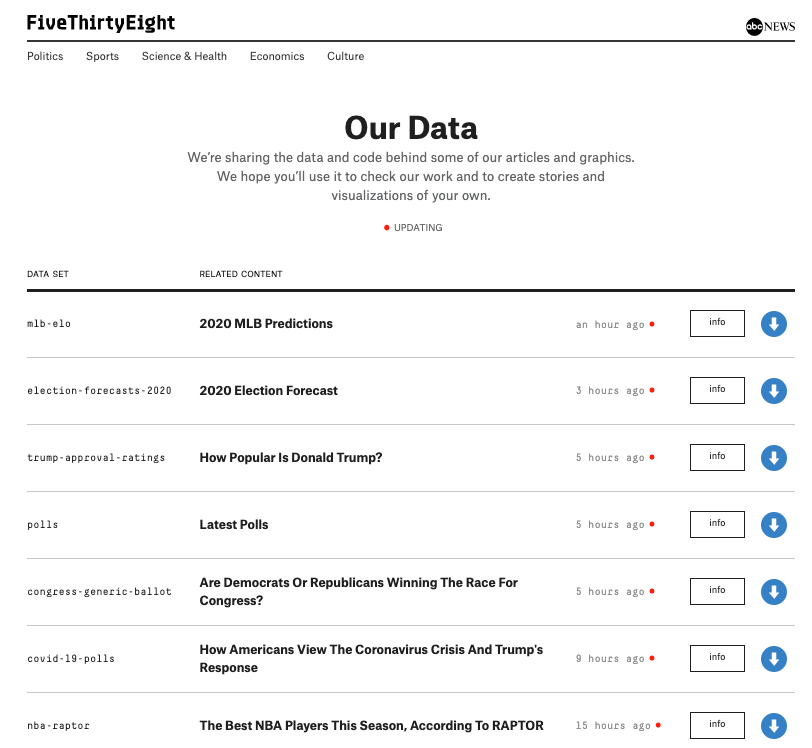
Open datasets on fivethirtyeight.com (Image by Author)
FiveThirtyEight is a site that hosts interactive articles. It presents some compelling analytical stories backed by interesting and curated datasets. These datasets have been made openly available for the public via their GitHub repository. Anybody can use these datasets and perform analysis of their own on topics ranging from politics to sports.
 fivethirtyeight.com dataset repository (Image by Author)
fivethirtyeight.com dataset repository (Image by Author)
View a FiveThirtyEight datasets demo.
Some of the interesting datasets on their site include the following:
- Airline safety dataset: the data behind the story, “Should Travelers Avoid Flying Airlines That Have Had Crashes in the Past?“
- Avengers: the data behind the story, “Joining The Avengers Is As Deadly As Jumping Off A Four-Story Building”
🔗 Link to the datasets: https://github.com/fivethirtyeight/data
4. Awesome-Public-Datasets on Github

The Awesome Public Dataset repository (Image by Author)
Awesome Public Datasets is a GitHub repository containing some high-quality public datasets that have been nicely curated by industry. The Repository notes:
This is a list of topic-centric public data sources in high quality. They are collected and tidied from blogs, answers, and user responses. Most of the data sets listed below are free; however, some are not.
Here is a quick look into some of the categories for which datasets are available in the repository:

Available dataset categories in awesome public dataset repository (Image by Author)
View an awesome public datasets demo.
🔗 Link to the datasets: https://github.com/awesomedata/awesome-public-datasets
5. BuzzFeed News
 https://www.buzzfeednews.com/ (Image by Author)
https://www.buzzfeednews.com/ (Image by Author)
BuzzFeed News is a news website published by BuzzFeed, an internet media, news, and entertainment company. BuzzFeed News features stories, and it has open-sourced the data, analysis, libraries, tools, and guides from those stories on GitHub.

BuzzFeedNews’ Repository containing open-source data, analysis, libraries, tools, and guides (Image by Author)
View a BuzzFeed News datasets demo.
You can find some interesting datasets, for instance:
- Presidential Campaign Contributions
- College Tuition and Minimum Wage Analysis
- Government Surveillance Planes Analysis
🔗 Link to the datasets: https://github.com/BuzzFeedNews/everything
Conclusion
These were some of the data aggregator sites that host open datasets. This is not an exhaustive list, but these are some of my favorites. If you are looking to work on some machine learning projects, I hope these sites will prove to be beneficial.
Originally published at parulpandey.com
About the Author
Parul Pandey , Weights & Biases
Parul is a Machine Learning Engineer at Weights & Biases working at the intersection of product, community, and developer advocacy.