The new Python in Excel integration allows embedding Python code directly into workbooks to work with our data. In this blog post, we will explore one of the most useful and innovative features this new integration unlocks: using regular expressions to search, replace, and validate your data. For example, regular expressions allow you to search for patterns within a text (instead of exact string values), or identify and extract specific parts (e.g., all the URLs within a text) to be checked and validated. Within Excel, regular expressions are a powerful tool for advanced data validation. We can use regular expressions to determine if our string data matches the desired format or criteria to prevent errors and uphold the integrity of data.
In this post, we will learn how to use regular expressions within Excel using the new Python in Excel integration. After reading this post, you will have a general understanding of regular expressions, and you will know how to use them in Excel to create custom data search and validation logic in your workbooks.
Note: To work on the examples presented in this post, please install the Python in Excel trial.
Introduction
Regular expressions (sometimes also referred to as REs, regex or regexp) are powerful tools for text data manipulation. A single regular expression consists of one or multiple sequences of characters, also known as the search pattern, used to describe the structure expected in the data. Search patterns are then used by string-searching algorithms to check and find any matching subsequence (substring) in the data. For this reason, regular expressions are generally adopted as a tool in data validation tasks. Typical use cases for regular expressions include validating date formats, email addresses, phone numbers, and any other data field that requires a specific (regular) pattern in its structure.
Microsoft Excel does not natively support regular expressions when searching or filtering data. Therefore, only exact text-based search is permitted. In this post, we will learn how the new Python in Excel integration allows the creation of custom logic functions using regular expressions directly in our workbook.
We will work with a publicly available company employee dataset, organized as an Excel Table. While we will learn how to use regular expressions to implement custom validation mechanisms on selected columns, we will also discover a few tips on efficient data processing with Python in Excel. But before diving into the practical hands-on parts, let’s first get our bearings with regular expressions and learn how to use them in Python.
Regular Expressions in Python: A Primer
At its very core, a regular expression is a string that uses a predetermined syntax of special characters and operators to define a pattern. A pattern is a formal description of the structure and the content of a text, based on various characteristics. Examples of these patterns are: “the list of allowed and/or not allowed characters in a string;” “how many times a certain sequence of characters can repeat within a word or a sentence;” or “the length of a given set of characters.” These patterns are then processed and aggregated by the regexp engine, to become the search pattern of the regular expression.
Regular expression patterns are defined using a very specific syntax including special characters (also referred to as meta-characters), and custom operators. For example, the expression [a-z] is a regular expression matching any single lowercase character from a to z. The square brackets delimit a single matching expression, also known as a character class. Although every modern programming language provides native support (i.e., without the need to install third-party packages) to regular expressions, the extent of this support may vary, along with the syntax used to define a search pattern. For this reason, in this post, we will consider the regex syntax as supported by the re Python package included with Python in Excel.
The regular expression syntax, and its corresponding list of symbols, is notoriously difficult for beginners, and sometimes cumbersome to remember even for expert users. But don’t worry; we will explain in detail every step in creating the regular expressions when working on our advanced data validation filters. In addition, we have created a practical cheat sheet that you can use to familiarize yourself with regular expressions, or in case you would need a refresher.
Using RegExp for Data Validation in Excel
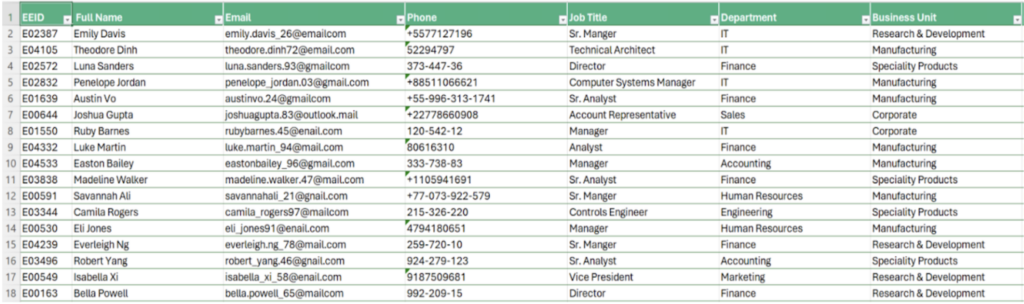
Figure 1: Preview of the example Company Employee data
Our dataset of synthetic company employee data is organized in 16 columns, namely Employee ID; Full Name; Email; Phone; Job Title; Department; Business Unit; Gender; Ethnicity; Age; Hire Date; Annual Salary (in USD); Bonus %; Department; Country; City; Exit Date. The whole dataset contains 1,000 rows, therefore it is reasonable to assume that we need automated methods to check and validate our data.
Looking at the preview of the data extracted from our workbook (see Figure 1), we can immediately identify some of the fields that can benefit from automated validation with regular expressions:
- The EEID column, namely the column containing the Employees’ IDs, seems a good candidate to start playing with regular expressions. An Employee ID is supposed to be 6 characters long, starting with a capital “E,” followed by five digits. Our job will be to define a regular expression that can capture this pattern in the data, and then run an automated validation for each cell.
- The Email column is another good candidate for regular expression validation. First, we need to check whether there are entries in our dataset that do not correspond to valid email addresses. Then, we can check whether all the email addresses are correct, so that they do not contain any typos. For example, a very common typo for email addresses is substituting the word mail with the word nail.
- 3. Checking the validity of Phone numbers will be perhaps the most interesting use case, from a regexp perspective. In fact
+1 111 123 4567; +1-111-123-4567; +1.111.123.4567; +11111234567;+1 (111) 1234567are all valid phone numbers, each characterized by variations in their formatting. Despite these variations, we will see how regular expressions make the validation of this data field very simple. Our challenge will be to define a single regular expression to capture all formats.
Getting ready
Before diving into the implementation, I would recommend that you disable Automatic Excel Formulas Calculations in your workbook. This will avoid performance bottlenecks—even accidental ones—when (automatically) executing your code, one entry at a time, on your data. To do so, please visit the menu File > Options > Formulas > Workbook Calculation and set it to Manual. Even though manual calculation mode may sometimes result in different calculations from automatic mode, this mode is recommended with the data at hand, so that the execution of the Python code on each table row will not freeze the environment.
EEID Validation
The first thing to bear in mind when working with Python in Excel is that the new integration provides a customized xl(“range”, headers) function to reference data in our workbook. This function will come in handy throughout our example as it will allow us to reference specific (range) of values in our workbook, automatically converted into Python objects, namely a DataFrame or a Series, accordingly. In this way, we can avoid processing one cell at a time, and instead operate on the whole DataFrame, with Python vectorized functions. Even though this may appear as a small difference, this will have a huge impact on performance. This strategy allows you to collect all the data into a unique data structure that will then be sent to the remote sandbox on Azure Cloud, instead of generating a lot of network traffic for small computations. Moreover, since cells are executed in a predefined order, the whole execution would run in sequence, rather than in parallel. While this would not count much when processing only a few entries, it will result in a huge bottleneck in performance when working on the whole dataset of 1,000 rows. So, keeping the Python in Excel execution model in mind is always important. For more information on the execution model, and other programming tips, please see this blog post.
All right! It’s finally time to write some Python code. First of all, let’s define our pattern. Matching an EEID is trivial using regular expressions: all EEID in fact can be captured by the following pattern: “E\d{5}” that reads “Capital letter E and 5 digits.” In more detail, the \d operator is used in regular expression syntax to denote a digit character, from 0 to 9; whereas we indicate the number of these characters that have to be in the string (i.e., the “quantifier”). In our case, it is five digits.
Let’s move on to the R1 cell to create a new =PY() cell, and write the following code:
df = xl("A1:A1001", headers=True)
pattern = "E\d{5}"
df.EEID.str.match(pattern)
First, we use the xl() function to select the entire EEID data column. This will be returned as a DataFrame, with a column with the same name. This is the result of passing headers=True in the xl function call. Then, we rely on pandas string function match to propagate the pattern matching across the multiple rows. Please note that this approach leverages entirely pandas internal optimizations for data loops, avoiding a much slower explicit iteration in Python. The result of the expression df.EEID.str.match(pattern) is a pandas series of boolean values, i.e., True or False, depending on whether the match was successful or unsuccessful, respectively. To see the values in our workbook, we can switch the Python cell output to “Excel value”. All values in the resulting series will be automatically spilled over the 1,000 rows by Excel. If you like, you could even use conditional formatting on those cells to highlight in green or red the result of the pattern matching.

Figure 2: EEID pattern validation. Please note the output of the cell is set to “Excel Value.”
Email Column Validation
When validating email addresses, we have two main objectives. First, we want to identify all the entries that contain invalid email addresses. An invalid email address is an entry in our data that does not match the email search pattern. Let’s define our search pattern first, and then we will explain it.
email_pattern = "[^\s@]+@[^\s@]+\.[^\s@]+$"
I know this may look daunting at first glance, but I promise it will become much simpler to understand if analyzed one component at a time. First, let’s notice that this regular expression makes use of character classes, which are identified by square brackets, i.e., [ ]. Character classes are a very handy feature of regexp syntax to identify multiple groups of expressions within a more general search pattern, the “email address pattern” in our case. Therefore, let’s analyze the whole pattern per each character class, left to right, so it will be easier to understand.
The first class (i.e., [^\s@]+) identifies any non-empty (i.e., the + quantifier) sequence of characters excluding whitespace and the @ symbol. (Please refer to the cheat sheet for further details on the ^, +, and the \s operators.) This pattern is very generic, as it allows an email account name to be as general as possible, including any alphanumeric or punctuation character. We don’t have any indication of restrictions that may have been imposed on the account names in our data, so we keep this pattern very broad and open to variations. The only character we don’t allow in the pattern is the whitespace (i.e., \s), as you cannot have spaces in your account name or an @ symbol, as this character has a very specific meaning in email addresses.
Afterward, we finally expect an @ symbol (i.e., @) in our email address candidate string, followed by the pattern for domain name–dot–domain-extension. In our email search pattern, we re-use an identical character class to match both domain names and extensions. Moreover, we use the backward slash meta-character (i.e., \.) to escape the dot character for matching.
The final code snippet to write in the S1 Python cell will be:
df = xl("C1:C1011", headers=True)
email_pattern = "[^\s@]+@[^\s@]+\.[^\s@]+$"
df["Email Validation"] = df.Email.str.match(pattern)
df["Email Validation"]
For the sole sake of having a better naming in the resulting column, this time we saved the result of pattern matching as a new “Email Validation” series into our original df dataframe, which will then be returned as the cell output. Using Excel conditional formatting, we can immediately identify entries with invalid email addresses.
Figure 3: Email validation results for invalid addresses, with conditional formatting.

Looking at the result, we may notice row 13 with an email address missing a dot in the domain name that is correctly identified as invalid. Interestingly though, this pattern is not able to capture email addresses that are valid but incorrect. For example, looking at row 12, Savannah’s email address is stored as @gnail.com. Therefore, we need to refine our validation procedure to include these cases too.
First, we would need to identify all the unique email domains we have in our data, and we will again use Python for that. Let’s write the following code in the U1 cell set as Python cell:
df = xl("C1:C1001", headers=True)
pattern = "[^\s@]+@[^\s@]+\.[^\s@]+$"
df["Email Validation"] = df.Email.str.match(pattern)
emails = df[df["Email Validation"] == True].Email.values
emails = set([e.split("@")[-1] for e in emails])
emails
This code will select all the emails, filtering out all those that are invalid using our previous search pattern; splits the entries on the @ symbol character, and retains the last (rightmost) part. Returning the results as a Python set will guarantee to get all the unique values. After running the cell, here is the result you should get:
mail.comoutlook.mail
gnail.comenail.comgmail.comemail.com
In our dataset, we have a total of six unique domains, some of which have typos in the mail word, as expected. Therefore, we could specialize our previous search pattern to make sure that all the domains match only the correct ones:
email_pattern = "^([^\s@]+)@((outlook\.mail)|([e|g]?mail\.com))$"
This time, we will leverage on regexp groups—identified in round parenthesis—to match all the parts in our email address pattern. In particular, the first group matches the account name, followed by the @ symbol and then domain groups. Domains are indeed matched as two alternative subgroups: the former for the outlook.mail domain, and the latter for the remaining three, namely mail.com, email.com, and gmail.com. Please notice how using perfectly crafted combinations of classes and quantifiers, we can match the three domains within a single group expression, that is matching either email or gmail or mail words using the “?” logic quantifier. If we use this new email pattern in our email validation code, we will identify invalid and incorrect email addresses, using a single regexp, resulting in more entries with errors.
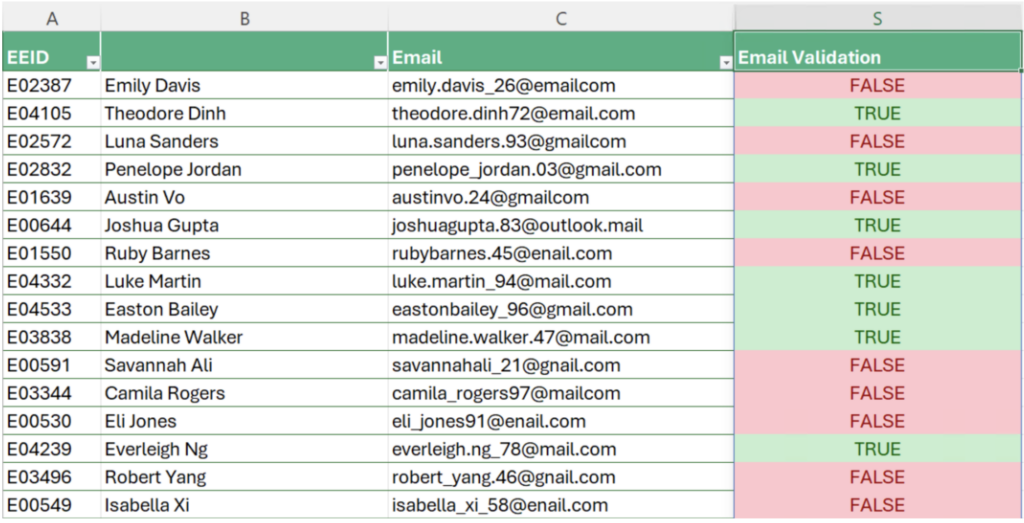
Figure 3: Email validation results for invalid and incorrect addresses.
- Phone Numbers Validation
Working on search patterns for phone numbers is interesting, as we can make use of all the regexp tools and tricks we have used so far. First, let’s list the main components of a phone number: the country code; the area code, and the local number. Similar to what we did when working on email address validation, we will construct the general search pattern for phone numbers by working on each single group at a time, in a divide-and-conquer manner.
Country codes are an optional component in phone numbers, composed of one or more digits, and typically preceded by a ‘+’ symbol. All this knowledge and consideration of our data format should be incorporated into the regex. A good candidate to match the country code group is
country_code_pattern = "(\+\d{1,3})?"
First, we use the backslash character to escape the parsing of the ‘+’ symbol (i.e., \+ ). This is necessary to avoid the regexp engine parsing the ‘+’ symbol as the quantifier operator. Then, we indicate the digits of the country code, which can be composed of one to three digits. Lastly, the whole group is marked as optional, using the ? logic operator.
The Area code instead is enclosed in optional parentheses and consists of digits whose length may vary depending on the country or the region. Let’s say the area code can be composed of one to four digits:
area_code_pattern = "\(?\d{1,4}\)?"
Please note the use of backward slashes to escape the matching of parentheses, made optional by the ? operator.
Local numbers are represented by a sequence of digits, separated into groups by optional separators such as spaces, dashes, or periods:
local_number_pattern = "\d{3}[\s.-]?\d{4}"
Please note the difference in the use of the quantifiers in this pattern, with respect to the previous examples. In this case, we are specifying the exact length of characters we are expecting to see in each group, namely 3 and 4. These digits are separated by an optional space, dot, or hyphen, as captured by the class [\s.-]?.
Putting those three groups together into a single search pattern, and also adopting delimiters for the start (^) and the end ($) of the string, we have our phone number search pattern:
phone_pattern = "^(\+\d{1,3})?\s?\(?\d{1,4}\)?[\s.-]?\d{3}[\s.-]?\d{4}$"
All we need to do now is to put this pattern to test on our data. Let’s create a new Python cell in T1 with the following code:
df = xl("D1:D1011", headers=True)
phone_pattern = "^(\+\d{1,3})?\s?\(?\d{1,4}\)?[\s.-]?\d{3}[\s.-]?\d{4}$"
df["Phone Validation"] = df.Phone.str.match(phone_pattern)
df["Phone Validation"]
Figure 4 shows an excerpt of the results on our data, highlighted with cell conditional formatting. It is worth noting how regular expressions are able to capture and validate the multiple variations in phone number formats. See for example how different the various correct numbers look at a first glance.
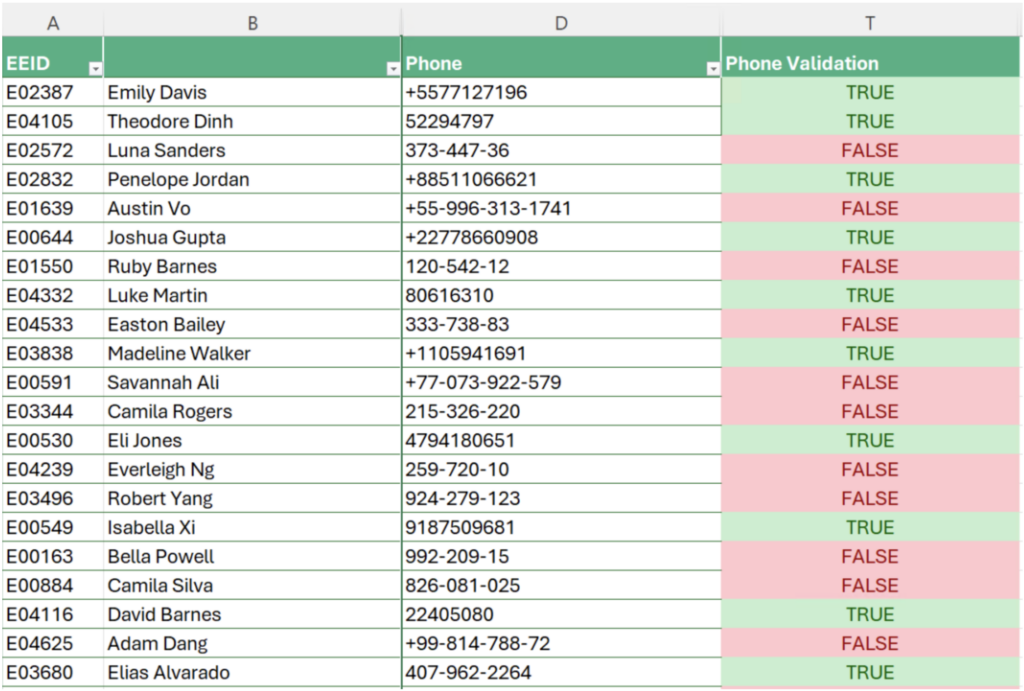
Figure 4: Phone number validation results
Conclusion
Regular expressions are extremely powerful tools for string data validation. With regular expressions, it is possible to check whether our data adheres to defined search patterns, intended as a combination of special operators and a sequence of characters. In this post, we have explored how the Python in Excel integration introduces this new capability directly into our workbooks to create automated data validation strategies. First, we have introduced the main concepts, and operators of regular expressions, such as meta-characters, character classes, and groups. We then demonstrated their use in an example case considering a company employee dataset of 1,000 entries. Using regular expressions, we have been able to identify typos and inconsistencies in our data, matching email addresses, employee IDs, and phone numbers. The complete version of the Excel workbook, including the Python code from examples is publicly available.